In questa pagina / On this page
L'accesso all'app è su invito: lista d'attesa F.A.I.T.H.
Versione tecnica — diario di laboratorio, settimana 3
Punto di partenza: dove avevamo lasciato Diablo
La settimana 2 si era chiusa con tre risultati concreti: controller RAID finalmente raffreddato, filesystem riportato in uno stato coerente dopo gli errori EXT4, e una prima RTX 3060 dichiarata morta dopo tutti i test possibili. Il log del kernel era pieno di Xid 79 e reset PCIe anche solo nei primi minuti di carico: non c'era niente da fare con il software.
La settimana 3 parte quindi da uno slot PCIe libero, un nodo termicamente sotto controllo e un array RAID6 che non sta più urlando. Non è molto, ma è abbastanza per ricominciare.
Da lunedì a mercoledì: burn-in della seconda RTX 3060
La seconda GPU è arrivata lunedì. Il protocollo di accettazione questa volta era esplicito: nessuna fiducia a priori, verifica su bus PCIe, temperatura a riposo, kernel log pulito e carico progressivo fino alla stabilità confermata su oltre 40 ore di uptime misto.
lspci | egrep 'NVIDIA|VGA'
# 01:00.0 VGA compatible controller: NVIDIA GeForce RTX 3060 (rev a1)
# 02:00.0 VGA compatible controller: NVIDIA GeForce RTX 3060 (rev a1)
nvidia-smi
# GPU 0 e 1: ~40–42°C a riposo, nessun processo, ~17–18W ciascuna
dmesg | grep -i nvidia | grep -i 'error\|xid\|reset' | tail -n 20
# (nessun output — kernel log pulito)Due schede viste correttamente, temperature di riposo sotto i 45°C, nessun Xid, nessun reset PCIe. Il contrasto con la scheda della settimana scorsa era immediato e definitivo.
watch -n 2 nvidia-smi
python run_gpu_stress.py
watch -n 10 'storcli /c0 show temperature | grep -i temp'Mercoledì sera: nessuna anomalia. La scheda è dichiarata sana.
Da giovedì a domenica: case chiuso e macchina in produzione
Da giovedì il case è rimasto fisicamente chiuso, con entrambe le GPU funzionanti dentro. La macchina non è più un banco di test aperto: è un nodo che lavora.
Diablo si accende via Wake-on-LAN quando serve e si spegne quando non c'è lavoro attivo. Tenere acceso hardware da oltre 300W in idle perché "potrebbe servire" non è sostenibile — e va contro il senso del progetto.

I modelli: Qwen3 e Cline su 8B
Il parco modelli si è consolidato intorno alla famiglia Qwen3 — il modello più leggero che completa correttamente ogni task:
| Modello | Dimensione | Uso principale |
|---|---|---|
qwen3:8b | 5.2 GB | Cline quotidiano, task veloci, Plan/Act |
qwen2.5-coder:14b | 9.0 GB | Code generation strutturato |
qwen2.5-coder:32b | 19 GB | Contesto lungo, ragionamento profondo |
qwen3-coder:30b | 18 GB | Task complessi multi-file |
Cline gira su qwen3:8b: un modello da 5 GB consuma una frazione di un 32B per lo stesso task elementare. Su un progetto che ha nel consumo energetico il tema centrale, questo conta.
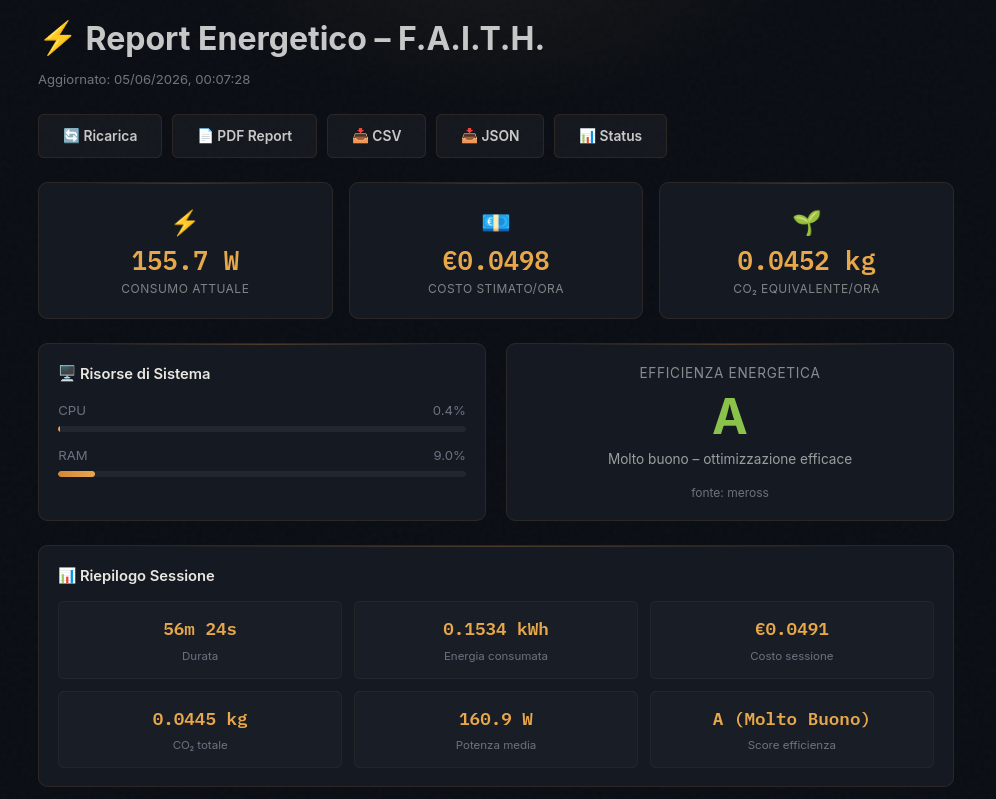
Il modulo energetico: misurare per confrontare
F.A.I.T.H. rende visibile il costo fisico dell'AI: GPU via NVML, CPU via psutil, assorbimento dalla presa quando disponibile tramite smart plug Meross in LAN (ordine di grandezza ~150W sotto carico GPU reale, non solo stima software).
Ogni operazione viene tracciata: tipo di task, modello, durata, energia in kWh, costo in euro, CO₂ equivalente. A fine sessione è possibile scaricare un report PDF con badge di efficienza e confronto con stime cloud per lo stesso workload.
In parallelo, la ricerca web passa da SearXNG locale a sintesi Ollama: risultati e risposta restano sul nodo, senza API esterne per il testo.
Il punto che conta: i tuoi dati restano tuoi
Per contratti, bilanci, dati medici o progetti non pubblici, spostare il confine del controllo dalla policy di un fornitore alla macchina che hai davanti ha senso concreto.
Cline che scrive F.A.I.T.H.
Buona parte del codice — incluso il modulo energetico — è stato scritto con Cline su questa macchina, modelli Qwen locali, ciclo Plan/Act. L'AI locale partecipa al proprio sviluppo senza inviare il codebase a API esterne.
Versione narrativa — quando la macchina smette di essere un cantiere
C'è un momento, in ogni progetto che parte dal recupero, in cui le cose smettono di essere un cantiere e cominciano ad assomigliare a qualcosa che funziona davvero. Per Diablo, questa è stata quella settimana.
Non è arrivata con un annuncio. È arrivata giovedì, quando ho avvitato il pannello del case e non l'ho più riaperto. Due GPU stabili, temperatura sotto controllo, log pulito. Una macchina che lavora.
Nelle settimane precedenti la domanda era "funziona ancora?". Questa settimana è diventata "cosa facciamo oggi?" — la differenza tra un esperimento e un'infrastruttura.
F.A.I.T.H. non è nata per essere il modo più economico di fare AI. È nata per rispondere a una domanda raramente posta con onestà: quanto costa davvero usare l'intelligenza artificiale — in energia, calore, infrastruttura fisica, non solo in abbonamento?
Questa settimana abbiamo iniziato a mettere i numeri sul tavolo: riposo, carico, euro, CO₂, confronto con stime cloud. Non per dire che il locale vince sempre — sarebbe disonesto — ma per rendere visibile ciò che di solito resta nascosto.
Poi la domanda ancora più concreta: dove finiscono i tuoi dati? Con F.A.I.T.H. restano sul rack. Il documento, la domanda, la risposta: elaborati lì, senza server intermedio obbligatorio.
Il dettaglio che mi ha colpito di più: il modulo che misura l'energia è stato scritto con Cline, qui, con modelli locali. L'AI locale costruisce lo strumento che misura l'AI locale. Il cerchio si chiude senza mandare il codice fuori rete.
Non è un risultato definitivo. È un punto di partenza concreto — anche quando parti da hardware che il mercato aveva già archiviato.
Technical version — week 3 lab notes
Week 1 covered reuse and RAID cooling; week 2 closed the filesystem and declared the first RTX 3060 dead after relentless Xid 79 events. Week 3 starts with a free PCIe slot, a thermally controlled node and a quiet RAID6 array — enough to move on.
The second GPU passed strict acceptance: clean dmesg, idle temps below 45°C, progressive stress, 40+ hours mixed uptime. By Wednesday the board was healthy; from Thursday the case stayed closed — a production node, not an open bench.
Wake-on-LAN keeps idle waste down. The model stack centers on Qwen3; Cline runs on qwen3:8b for everyday work because a 5 GB model draws a fraction of a 32B for the same simple task.
The energy module tracks real wall draw when the Meross plug is available, plus NVML/psutil, PDF reports and cloud comparisons. Web search uses local SearXNG plus Ollama synthesis — no external LLM API for the answer text.
Much of the codebase — including the energy module — was written with Cline on this machine using local Qwen models (Plan/Act), closing the sustainability loop: reused hardware, local data, local development.
Narrative version — when the machine stops being a construction site
In reuse-driven projects, there is a moment when things stop looking like a construction site. For Diablo, that was this week — closed case, two stable GPUs, clean logs, real work.
F.A.I.T.H. was built to ask what AI really costs in physical terms, and where your data go when you hand them to a cloud service. This week we started measuring our own stack honestly and keeping inference on the machine in the rack.
The detail that mattered most: the energy module that measures local AI was written with local AI on the same box. Not a finale — a concrete starting point on hardware the market had written off.